

Hadoop是一个由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架; Hadoop以一种可靠....

开篇三连问!· 你觉得视频终端只能开视频会议,并一定要复杂的有线连接吗?· 你觉得视频终端和智能化应用不靠边,终端外形跟....

摘要Spark Streaming是一套优秀的实时计算框架。其良好的可扩展性、高吞吐量以及容错机制能够满足我们很多的场景应用。本篇....
需求场景:我们的产品需要与客户的权限系统对接,即在登录时使用客户的认证系统进行认证。集成认证的方式是调用客户提供的ja....

一个新的项目旨在为实时处理开发一种速度更快的框架,可用来支持用Python编写的机器学习应用。加州大学伯克利分校实时智能安....

随着对spark的业务更深入,对spark的了解也越多,然而目前还处于知道的越多,不知道的更多阶段,当然这也是成长最快的阶段。....

这一个月我都干了些什么……工作上,还是一如既往的写bug并不亦乐乎的修bug。学习上,最近看了一些非专业书籍,写点小感悟,....

我是51CTO学院讲师张敏,在51CTO学院 “4.20 IT充电节”(4月19~20日) 到来之际,和大家分享一下Spark Core之上扩建自己的模....

译者注:本文介绍了两大常用的流式处理框架,Spark Streaming和Kafka Stream,并对他们各自的特点做了详细说明,以帮助读者....

最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑。为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结....

0、背景集群部分 spark 任务执行很慢,且经常出错,参数改来改去怎么都无法优化其性能和解决频繁随机报错的问题。看了下任务....

在复杂业务逻辑中,我们经常会用到Spark的UDF,当一个UDF需要传入多列的内容并进行处理时,UDF的传参该怎么做呢? 下面通过....

Spark:Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的....

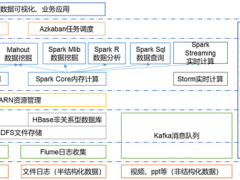
【51CTO.com原创稿件】2013 年,苏宁大数据团队以 Hadoop 生态系统为核心构建了整套大数据平台,为整个苏宁集团所有业务团队....

本文将简要介绍Spark机器学习库(Spark MLlib’s APIs)的各种机器学习算法,主要包括:统计算法、分类算法、聚类算法和协同....
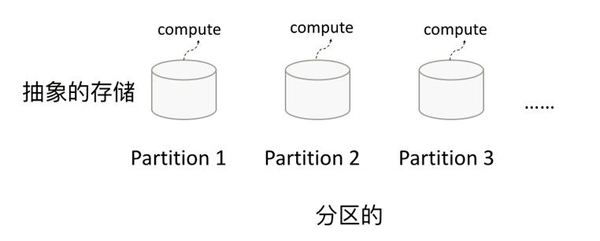
RDD全称叫做弹性分布式数据集(Resilient Distributed Datasets),它是一种分布式的内存抽象,表示一个只读的记录分区的集合....

前言最近工作中是做日志分析的平台,采用了sparkstreaming+kafka,采用kafka主要是看中了它对大数据量处理的高性能,处理日....

为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入....

Executor 端的内存模型,包括堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。存管理接口(MemoryManager )Spark 为Exe....

概 况Spark 是最活跃的 Apache 项目之一。从 2014 年左右开始得到广泛关注。Spark 的开源社区一度达到上千的活跃贡献者。最....
文库吧 版权所有 (c)2021-2022 ICP备案号:晋ICP备2021003244-6号


