


Spark Streaming是基于微批处理的流式计算引擎,通常是利用Spark Core或者Spark Core与Spark Sql一起来处理数据。在企业实时....

【编者的话】本文是在Kubernets上搭建Spark集群的操作指南,同时提供了Spark测试任务及相关的测试数据,通过阅读本文,你可....

1、前言在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批....

一 内容简介spark从1.6开始引入了动态内存管理模式,即执行内存和存储内存之间可以互相抢占。spark提供两种内存分配模式:静....

本论文从分布式系统的角度开展针对当前一些机器学习平台的研究,综述了这些平台所使用的架构设计,对这些平台在通信和控制上....

面临的场景金融风控 用户画像库 爬虫抓取信息 反欺诈系统 订单数据个性化推荐 用户行为分析 用户画像 ....

背景相信经常使用 Spark 的同学肯定知道 Spark 支持将作业的 event log 保存到持久化设备。默认这个功能是关闭的,不过我们....

RDD简介RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里....

什么是数据倾斜?对 Spark/Hadoop 这样的分布式大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。对于分布式系统而言,....
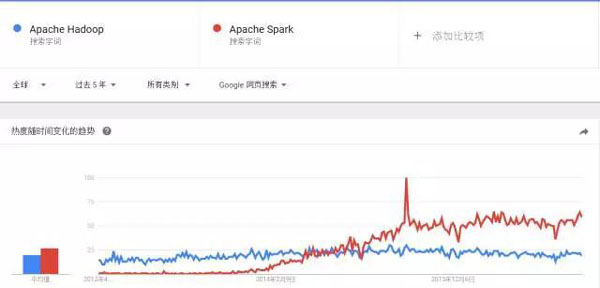
最近几年关于Apache Spark框架的声音是越来越多,而且慢慢地成为大数据领域的主流系统。最近几年Apache Spark和Apache Hado....

在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶....

前言统计科学家使用交互式的统计工具(比如R)来回答数据中的问题,获得全景的认识。与之相比,数据工程师则更像一名程序员,....

【51CTO.com快译】几乎所有技术决策都要满足两个基本标准:让企业能够实现业务目标,与技术架构的其余部分协同运行。说到选....

很多用Spark Streaming 的朋友应该使用过broadcast,大多数情况下广播变量都是以单例模式声明的有没有粉丝想过为什么?浪尖....

####背景:####spark graphx并未提供极大团挖掘算法当下的极大团算法都是串行化的算法,基于Bron–Kerbosch算法####思路:####s....

大数据处理的新趋势,流处理和批处理是非常重要的两个概念,而基于流处理和批处理的大数据处理框架,Flink和Spark,也是常常....

下一代大数据计算引擎自从数据处理需求超过了传统数据库能有效处理的数据量之后,Hadoop 等各种基于 MapReduce 的海量数据处....

spark程序是使用一个spark应用实例一次性对一批历史数据进行处理,spark streaming是将持续不断输入的数据流转换成多个batc....

前言这两年做 streamingpro 时,不可避免的需要对Spark做大量的增强。就如同我之前吐槽的,Spark大量使用了new进行对象的创....

0、背景日前接到反馈,集群部分 spark 任务执行很慢,且经常出错,参数改来改去怎么都无法优化其性能和解决频繁随机报错的问....
文库吧 版权所有 (c)2021-2022 ICP备案号:晋ICP备2021003244-6号


