


一、概述Spark 作为一个基于内存的分布式计算引擎,其内存管理模块在整个系统中扮演着非常重要的角色。理解 Spark 内存管理....

一.内容简介spark从1.6开始引入了动态内存管理模式,即执行内存和存储内存之间可以互相抢占。spark提供两种内存分配模式:静....

BlazingSQL 是基于英伟达 RAPIDS 生态系统构建的 GPU 加速 SQL 引擎,可以为各种 ETL 大数据集提供 SQL 接口,并且完全运行....

Spark有几种资源调度设施。每个Spark Application(SparkContext实例)独立地运行在一组executor进程内。cluster manager为应....

内存不过是计算机分级存储系统中的靠近cpu的一个存储介质。 spark运行起来内存里都存的啥? 如何管理里面所存的东西? ....

内存不过是计算机分级存储系统中的靠近cpu的一个存储介质1.spark运行起来内存里都存的啥?2.如何管理里面所存的东西?3.spark....

在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位。Spark的这种学....
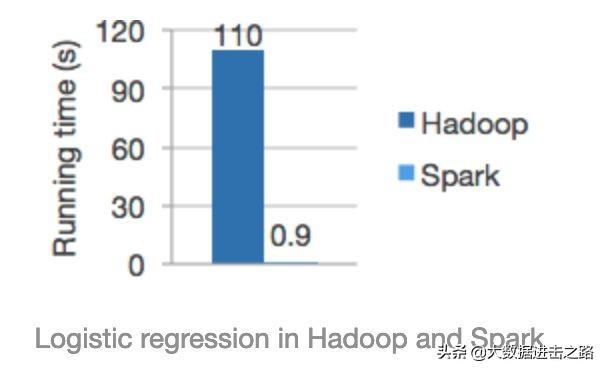
1 简介Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。它产生于 UC Berkeley AMP Lab,继承了 MapReduce ....
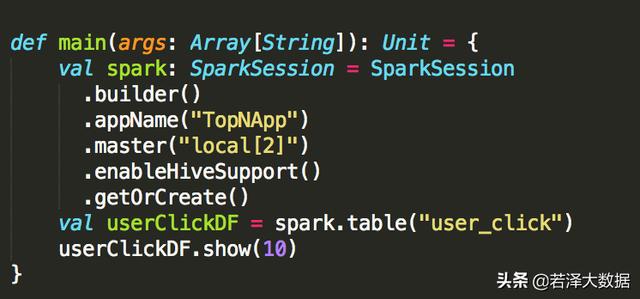
需要先将hadoop的core-site.xml,hive的hive-site.xml拷贝到project中测试代码 报错 查看源码 解决方法将$HIVE_HOME/lib....

RDD特征概要总结:a、RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集。b、RDD在抽象....

在面向流处理的分布式计算中,经常会有这种需求,希望需要处理的某个数据集能够不随着流式数据的流逝而消失。以spark stream....

collect返回RDD的所有元素scala> var input=sc.parallelize(Array(-1,0,1,2,2)) input: org.apache.spark.rdd.RDD[Int]....

Hive和Spark凭借其在处理大规模数据方面的优势大获成功,换句话说,它们是做大数据分析的。本文重点阐述这两种产品的发展史....

概览Spark Streaming是Spark API的一个可横向扩容,高吞吐量,容错的实时数据流处理引擎,Spark能够从Kafka、Flume、Kinesi....

今天是2019年,要是有谁说有十年大数据工作经验,我是不信的。因为 Spark 正式应用才多少年?看过下面文章的你,应该就知道了....

一、前言Spark 作为大数据计算引擎,凭借其快速、稳定、简易等特点,快速的占领了大数据计算的领域。本文主要为作者在搭建使....

1.背景介绍PV/UV统计是流式分析一个常见的场景。通过PV可以对访问的网站做流量或热点分析,例如广告主可以通过PV值预估投放....
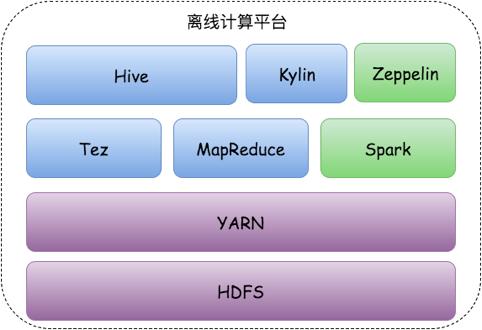
前言美团最初的数据处理以Hive SQL为主,底层计算引擎为MapReduce,部分相对复杂的业务会由工程师编写MapReduce程序实现。随....

一、Spark内存管理模式Spark有两种内存管理模式,静态内存管理(Static MemoryManager)和动态(统一)内存管理(Unified Memo....

相较于Scala语言而言,Python具有其独有的优势及广泛应用性,因此Spark也推出了PySpark,在框架上提供了利用Python语言的接....
文库吧 版权所有 (c)2021-2022 ICP备案号:晋ICP备2021003244-6号


